






We present ART•V, an efficient framework for auto-regressive video generation with diffusion models. Unlike existing methods that generate entire videos in one-shot, ART•V generates a single frame at a time, conditioned on the previous ones.
The framework offers three distinct advantages. First, it only learns simple continual motions between adjacent frames, therefore avoiding modeling complex long-range motions that require huge training data. Second, it preserves the high-fidelity generation ability of the pre-trained image diffusion models by making only minimal network modifications. Third, it can generate arbitrarily long videos conditioned on a variety of prompts such as text, image or their combinations, making it highly versatile and flexible.
To combat the common drifting issue in AR models, we propose masked diffusion model which implicitly learns which information can be drawn from reference images rather than network predictions, in order to reduce the risk of generating inconsistent appearances that cause drifting. Moreover, we further enhance generation coherence by conditioning it on the initial frame, which typically contains minimal noise. This is particularly useful for long video generation.
When trained for only two weeks on four A100 GPUs, ART•V already can generate videos with natural motions, rich details and a high level of aesthetic quality. Besides, it enables various appealing applications, e.g. composing a long video from multiple text prompts and animating single images based on descriptive texts.
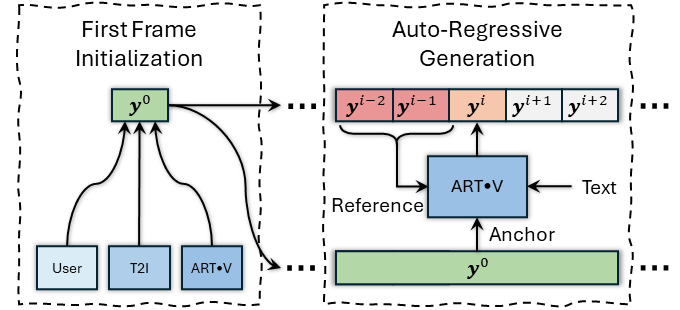
System overview
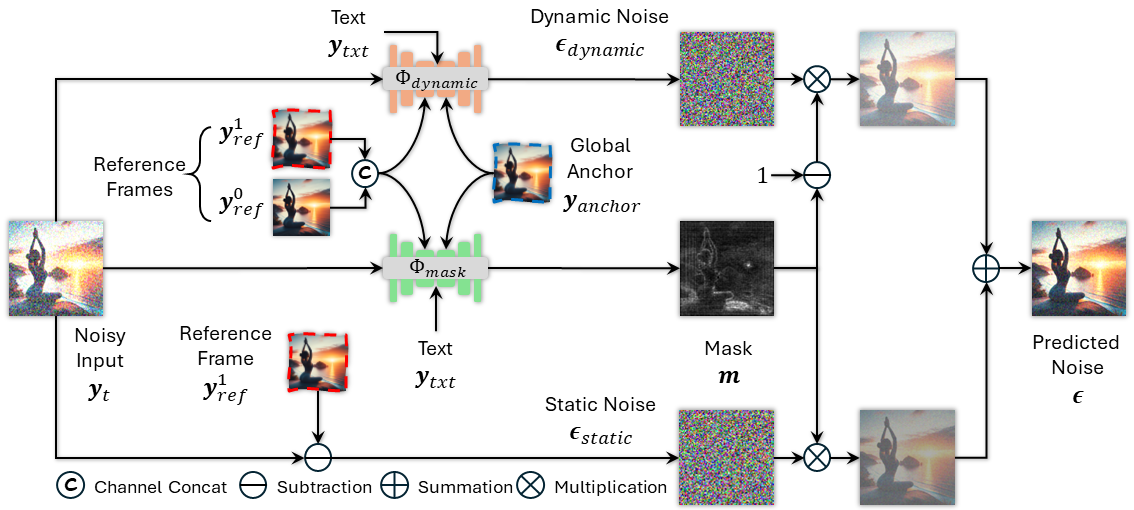
Masked diffusion model
ART•V is able to support text-to-video generation, without the image provided by T2I models or users. We make comparisons with one promising method ModelScope.

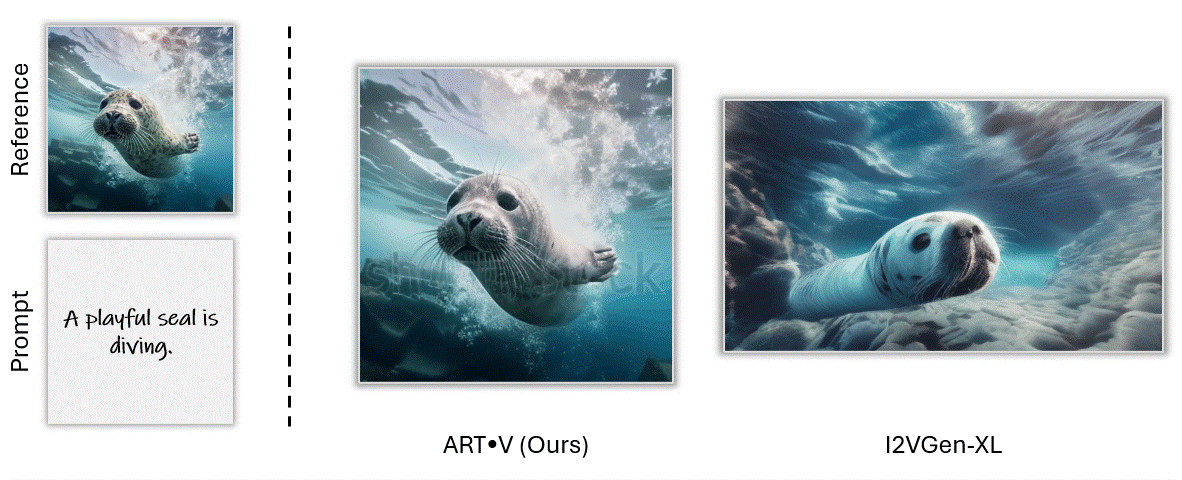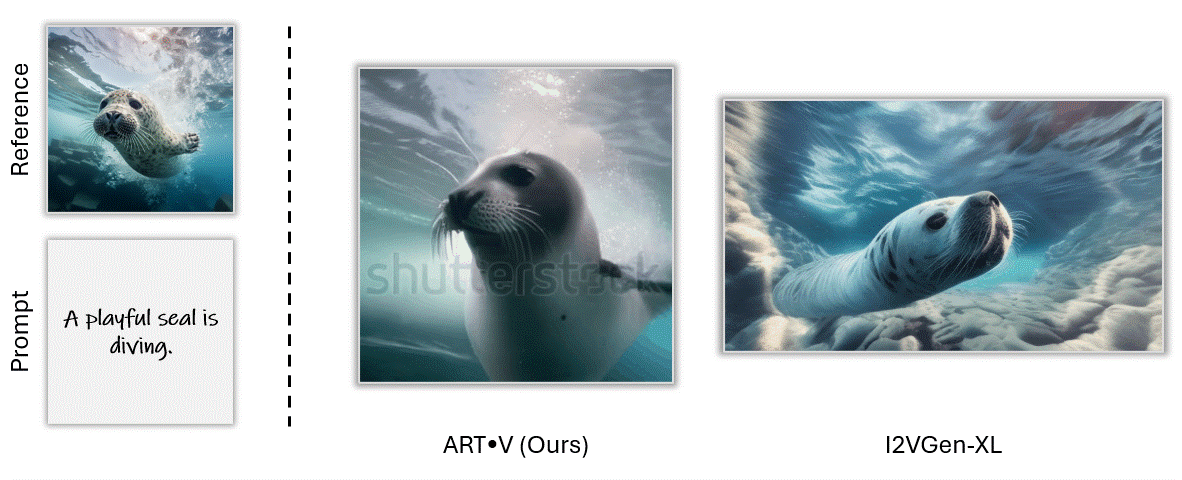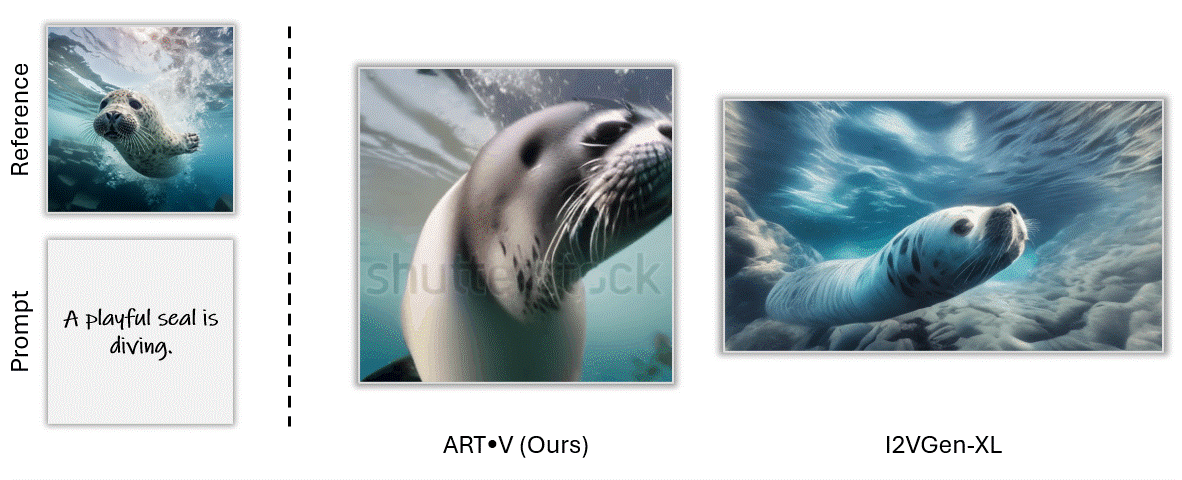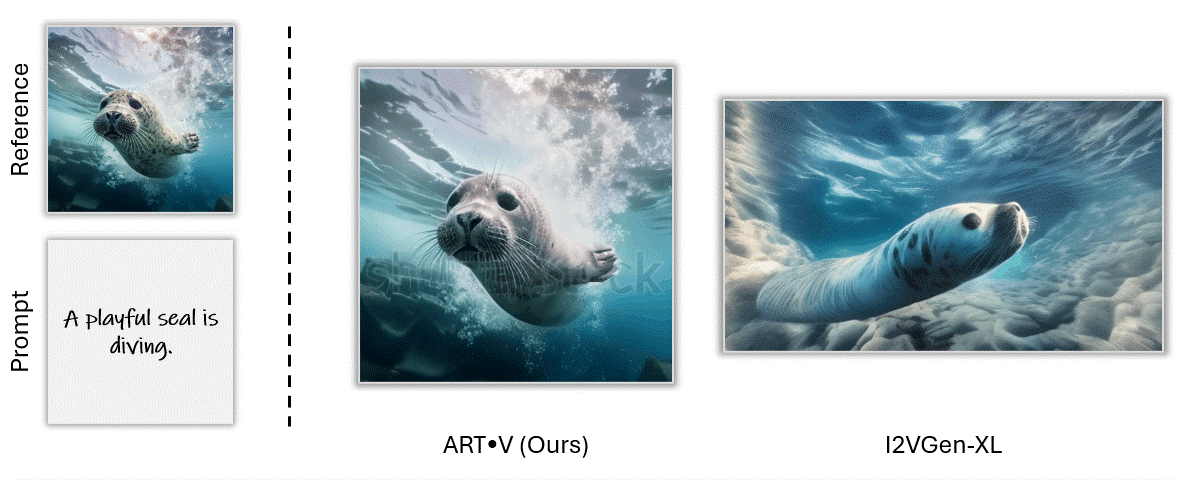
ART•V also offers the ability to animate a still image based on text prompts. We make comparisons with one powerful image-to-video method I2VGenXL.















ART•V is suitable for long video generation given multiple prompts, due to its auto-regressive nature. We can see that ART•V can generate videos with coherent scenes and objects, where the motions are faithful to the corresponding prompts.

We provide more visualizations of mask predicted by masked diffusion model. The maximal sampling step is 50. Particularly, the black area of the mask has the low value, which means the motion area that needs to be predicted by dynamic noise prediction network. In contrast, the bright area of the mask has the high value, which can be directly copied from the reference frame.

@article{park2021nerfies,
author = {Weng, Wenming and Feng, Ruoyu and Wang, Yanhui and Dai, Qi and Wang, Chunyu and Yin, Dacheng and Zhao, Zhiyuan and Qiu, Kai and Bao, Jianmin and Yuan, Yuhui and Luo, Chong and Zhang, Yueyi and Xiong, Zhiwei},
title = {ART•V: Auto-Regressive Text-to-Video Generation with Diffusion Models},
journal = {arXiv preprint arXiv:2311.18834},
year = {2023},
}